

Comment fonctionne le classement de recherche Google ou l’Autopsie du cerveau de google
Contenu issu de la traduction de https://searchengineland.com/how-google-search-ranking-works-445141 Mario Fischer le 13 août 2024
Une analyse approfondie du fonctionnement du système de classement complexe de Google et des composants tels que Twiddlers et NavBoost qui influencent les résultats de recherche.
Il devrait être clair pour tout le monde que la fuite de documentation de Google et les documents publics des audiences antitrust ne nous disent pas vraiment comment fonctionnent exactement les classements.
La structure des résultats de recherche organiques est aujourd’hui si complexe – notamment en raison de l’utilisation de l’apprentissage automatique – que même les employés de Google qui travaillent sur les algorithmes de classement affirment qu’ils ne peuvent plus expliquer pourquoi un résultat se situe à la première ou à la deuxième place. Nous ne connaissons pas la pondération des nombreux signaux ni leur interaction exacte.
Il est néanmoins important de se familiariser avec la structure du moteur de recherche pour comprendre pourquoi des pages bien optimisées ne sont pas classées ou, à l’inverse, pourquoi des résultats apparemment courts et non optimisés apparaissent parfois en haut des classements. L’aspect le plus important est que vous devez élargir votre vision de ce qui est vraiment important.
Toutes les informations disponibles le montrent clairement. Toute personne qui s’intéresse de près ou de loin au classement devrait intégrer ces résultats dans sa propre réflexion. Vous verrez vos sites Web sous un angle complètement différent et intégrerez des mesures supplémentaires dans vos analyses, votre planification et vos décisions.
Pour être honnête , il est extrêmement difficile de dresser un tableau vraiment valable de la structure des systèmes. Les informations sur le Web sont très différentes dans leur interprétation et parfois dans leurs termes, même si elles veulent dire la même chose.
Un exemple : le système chargé de construire une SERP (page de résultats de recherche) qui optimise l’utilisation de l’espace s’appelle Tangram. Dans certains documents Google, il est cependant également appelé Tetris, ce qui est probablement une référence au jeu bien connu.
Au cours de semaines de travail minutieux, j’ai consulté, analysé, structuré, rejeté et restructuré près de 100 documents à plusieurs reprises.
Cet article n’a pas vocation à être exhaustif ou strictement exact. Il représente mes meilleurs efforts (c’est-à-dire « au mieux de mes connaissances et convictions ») et un peu de l’esprit d’enquête de l’inspecteur Columbo. Le résultat est ce que vous voyez ici.
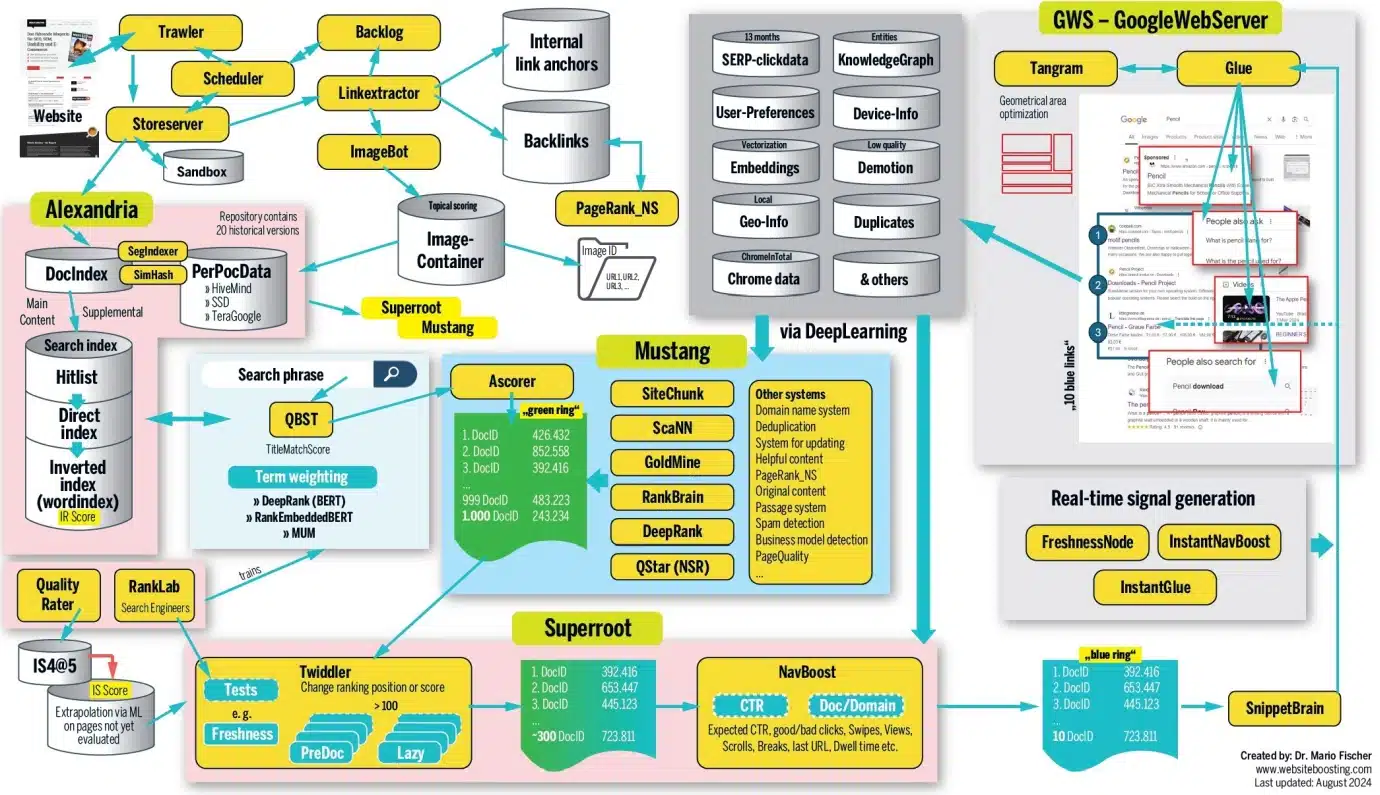
Un aperçu graphique du fonctionnement du classement Google, créé par l’auteur
Un nouveau document en attente de la visite de Googlebot
Lorsque vous publiez un nouveau site Web, il n’est pas indexé immédiatement. Google doit d’abord prendre connaissance de l’URL. Cela se produit généralement via un plan de site mis à jour ou via un lien placé à partir d’une URL déjà connue.
Les pages fréquemment visitées, comme la page d’accueil, attirent naturellement plus rapidement l’attention de Google sur ces informations de lien.
Le système de trawler récupère le nouveau contenu et garde une trace du moment où il faut revisiter l’URL pour vérifier les mises à jour. Ceci est géré par un composant appelé planificateur. Le serveur de stockage décide si l’URL est transférée ou si elle est placée dans le sandbox.
Google nie l’existence de cette boîte, mais les fuites récentes suggèrent que des sites de spam (suspectés) et des sites de faible valeur y sont placés. Il convient de mentionner que Google transmet apparemment une partie du spam, probablement pour une analyse plus approfondie afin d’entraîner ses algorithmes.
Notre document fictif franchit cette barrière. Les liens sortants de notre document sont extraits et triés selon qu’ils sont internes ou externes. D’autres systèmes utilisent principalement ces informations pour l’analyse des liens et le calcul du PageRank. (Plus d’informations à ce sujet plus tard.)
Les liens vers les images sont transmis à l’ImageBot, qui les appelle, parfois avec un retard important, et ils sont placés (avec des images identiques ou similaires) dans un conteneur d’images. Trawler utilise apparemment son propre PageRank pour ajuster la fréquence d’exploration. Si un site Web a plus de trafic, cette fréquence d’exploration augmente ( ClientTrafficFraction ).
Alexandrie : La grande bibliothèque
Le système d’indexation de Google, appelé Alexandria, attribue un DocID unique à chaque élément de contenu. Si le contenu est déjà connu, comme dans le cas de doublons, aucun nouvel ID n’est créé ; à la place, l’URL est liée au DocID existant.
Important : Google fait la différence entre une URL et un document. Un document peut être composé de plusieurs URL contenant un contenu similaire, y compris des versions linguistiques différentes, si elles sont correctement marquées. Les URL d’autres domaines sont également triées ici. Tous les signaux de ces URL sont appliqués via le DocID commun.
Pour les contenus dupliqués, Google sélectionne la version canonique, qui apparaît dans les classements de recherche. Cela explique également pourquoi d’autres URL peuvent parfois être classées de manière similaire ; la détermination de l’URL « d’origine » (canonique) peut changer au fil du temps.

Comme il n’existe qu’une seule version de notre document sur le Web, elle dispose de son propre DocID.
Les segments individuels de notre site sont parcourus à la recherche de mots-clés pertinents et intégrés à l’index de recherche. La « liste de résultats » (tous les mots clés importants de la page) est d’abord envoyée à l’index direct, qui résume les mots-clés qui apparaissent plusieurs fois par page.
Une étape importante est maintenant franchie. Les expressions-clés individuelles sont intégrées dans le catalogue de mots de l’index inversé (index des mots). Le mot slip de bain et tous les documents importants contenant ce mot y sont déjà répertoriés.
En termes simples, comme notre document contient le mot slip de bain à plusieurs reprises, il est désormais répertorié dans l’index des mots avec son DocID sous l’entrée « slip de bain ».
Le DocID est associé à un score IR (recherche d’informations) calculé par algorithme pour le slip de bain, utilisé ultérieurement pour l’inclusion dans la liste de publication. Dans notre document, par exemple, le mot slip de bain a été marqué en gras dans le texte et est contenu dans H1 (stocké dans AvrTermWeight ). Ces signaux et d’autres augmentent le score IR.
Google déplace les documents considérés comme importants vers ce qu’on appelle HiveMind, c’est-à-dire la mémoire principale. Google utilise à la fois des SSD rapides et des disques durs classiques (appelés TeraGoogle) pour le stockage à long terme des informations qui ne nécessitent pas d’accès rapide. Les documents et les signaux sont stockés dans la mémoire principale.
Les experts estiment qu’avant le récent boom de l’intelligence artificielle, environ la moitié des serveurs Web du monde entier étaient hébergés chez Google. Un vaste réseau de clusters interconnectés permet à des millions d’unités de mémoire principale de fonctionner ensemble. Un ingénieur de Google a fait remarquer un jour lors d’une conférence que, en théorie, la mémoire principale de Google pourrait stocker l’intégralité du Web.
Il est intéressant de noter que les liens, y compris les backlinks, stockés dans HiveMind semblent avoir beaucoup plus de poids. Par exemple, les liens provenant de documents importants ont une importance beaucoup plus grande, tandis que les liens provenant d’URL dans TeraGoogle (HDD) peuvent avoir moins de poids, voire ne pas être pris en compte du tout.
- Astuce : fournissez à vos documents des valeurs de date plausibles et cohérentes. BylineDate (date dans le code source), syntaticDate (date extraite de l’URL et/ou du titre) et semanticDate (extraite du contenu lisible) sont utilisées, entre autres.
- Le fait de simuler l’actualité en modifiant la date peut certainement conduire à une rétrogradation. L’ attribut lastSignificantUpdate enregistre la date de la dernière modification significative apportée à un document. La correction de détails mineurs ou de fautes de frappe n’affecte pas ce compteur.
Des informations et des signaux supplémentaires pour chaque DocID sont stockés de manière dynamique dans le référentiel ( PerDocData ). De nombreux systèmes y accèdent ultérieurement pour affiner la pertinence. Il est utile de savoir que les 20 dernières versions d’un document y sont stockées (via CrawlerChangerateURLHistory ).
Google est capable d’évaluer et de juger les changements au fil du temps. Si vous souhaitez modifier complètement le contenu ou le sujet d’un document, vous devrez théoriquement créer 20 versions intermédiaires pour remplacer les anciens signaux de contenu. C’est pourquoi réactiver un domaine expiré (un domaine qui était auparavant actif mais qui a depuis été abandonné ou vendu, peut-être en raison d’une insolvabilité) n’offre aucun avantage de classement.
Si le C Admin d’un domaine change et que son contenu thématique change en même temps, une machine peut facilement le détecter à ce stade. Google met alors tous les signaux à zéro et l’ancien domaine, supposé précieux, n’offre plus aucun avantage par rapport à un domaine entièrement nouvellement enregistré.
QBST : Quelqu’un cherche un « slip de bain »
Lorsqu’un internaute saisit le terme de recherche « slip de bain » dans Google, QBST commence son travail. La phrase de recherche est analysée et, si elle contient plusieurs mots, les mots pertinents sont envoyés à l’index de mots pour être récupérés.
Le processus de pondération des termes est assez complexe et fait appel à des systèmes tels que RankBrain, DeepRank (anciennement BERT) et RankEmbeddedBERT. Les termes pertinents, tels que « slip de bain », sont ensuite transmis à l’Ascorer pour un traitement ultérieur.
Ascorer : Le « cercle vert » est créé
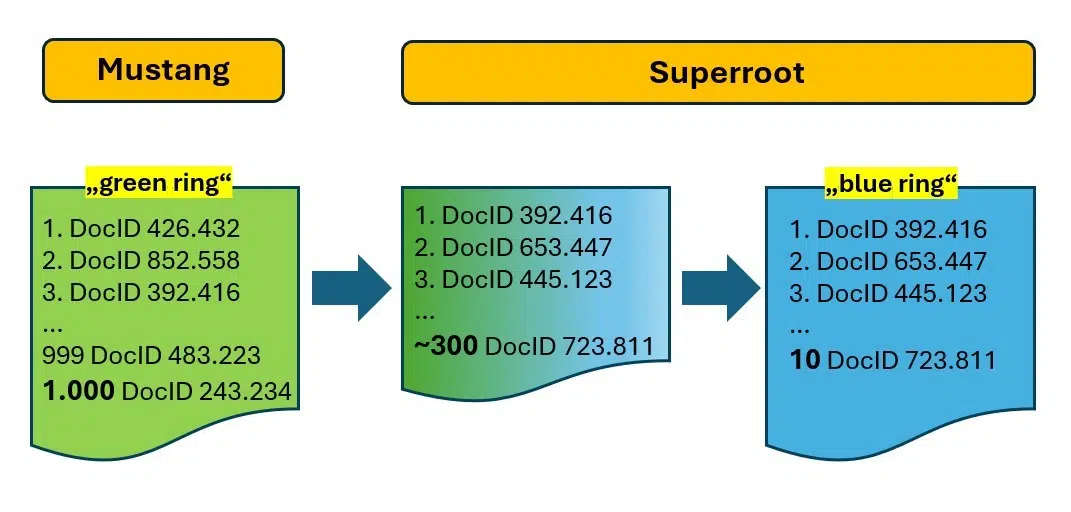
L’Ascorer récupère les 1 000 premiers DocID pour « slip de bain » à partir de l’index inversé, classés par score IR. Selon des documents internes, cette liste est appelée « anneau vert ». Dans le secteur, elle est connue sous le nom de liste de publication.
L’Ascorer fait partie d’un système de classement connu sous le nom de Mustang, où un filtrage supplémentaire s’effectue via des méthodes telles que la déduplication à l’aide de SimHash (un type d’empreinte digitale de document), l’analyse de passage, les systèmes de reconnaissance de contenu original et utile, etc. L’objectif est d’affiner les 1 000 candidats jusqu’aux « 10 liens bleus » ou à « l’anneau bleu ».
Notre document sur les slip de bain est sur la liste d’affichage, actuellement classé à la 132e place. Sans systèmes supplémentaires, ce serait sa position finale.
Superroot : Transformez 1 000 en 10 !
Le système Superroot est responsable du reclassement, en effectuant le travail de précision consistant à réduire « l’anneau vert » (1 000 DocID) à « l’anneau bleu » avec seulement 10 résultats.
Twiddlers et NavBoost effectuent cette tâche. D’autres systèmes sont probablement utilisés ici, mais leurs détails exacts ne sont pas clairs en raison d’informations vagues.
- Google Caffeine n’existe plus sous cette forme. Seul le nom est resté.
- Google travaille désormais avec d’innombrables microservices qui communiquent entre eux et génèrent des attributs pour les documents qui sont utilisés comme signaux par une grande variété de systèmes de classement et de reclassement et avec lesquels les réseaux neuronaux sont formés pour faire des prédictions.
Filtre après filtre : Les Twiddlers
Plusieurs documents indiquent que plusieurs centaines de systèmes Twiddler sont utilisés. Considérez un Twiddler comme un plug-in similaire à ceux de WordPress.
Chaque Twiddler possède sa propre cible de filtrage spécifique. Ils sont conçus de cette façon car ils sont relativement faciles à créer et ne nécessitent pas de modifications des algorithmes de classement complexes d’Ascorer.
La modification de ces algorithmes est difficile et nécessiterait une planification et une programmation approfondies en raison des effets secondaires potentiels. En revanche, les Twiddlers fonctionnent en parallèle ou de manière séquentielle et ne sont pas au courant des activités des autres Twiddlers.
Il existe essentiellement deux types de Twiddlers.
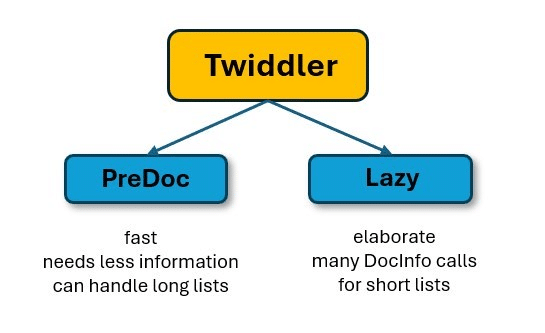
- Les PreDoc Twiddlers peuvent travailler avec l’ensemble complet de plusieurs centaines de DocID car ils nécessitent peu ou pas d’informations supplémentaires.
- En revanche, les Twiddlers de type « Lazy » ont besoin de plus d’informations, par exemple de la base de données PerDocData . Cela prend donc plus de temps et est plus complexe.
Pour cette raison, les PreDocs réduisent d’abord la liste de publication à un nombre nettement inférieur d’entrées, puis commencent avec des filtres plus lents. Cela permet d’économiser énormément de capacité de calcul et de temps.
Certains Twiddlers ajustent le score IR, soit positivement, soit négativement, tandis que d’autres modifient directement la position dans le classement. Comme notre document est nouveau dans l’index, un Twiddler conçu pour donner aux documents récents une meilleure chance de classement pourrait, par exemple, multiplier le score IR par un facteur de 1,7. Cet ajustement pourrait faire passer notre document de la 132e à la 81e place.
Un autre Twiddler améliore la diversité ( strideCategory ) dans les SERP en dévalorisant les documents au contenu similaire. En conséquence, plusieurs documents devant nous perdent leur position, ce qui permet à notre document slip de bain de monter de 12 places à la 69e place. De plus, un Twiddler qui limite le nombre de pages de blog à trois pour des requêtes spécifiques augmente notre classement à la 61e place.
Notre page a reçu un zéro (pour « Oui ») pour l’ attribut CommercialScore . Le système Mustang a identifié une intention de vente lors de l’analyse. Google sait probablement que les recherches pour « slip de bain » sont fréquemment suivies de recherches plus précises comme « acheter un slip de bain », ce qui indique une intention commerciale ou transactionnelle. Un Twiddler conçu pour tenir compte de cette intention de recherche ajoute des résultats pertinents et améliore notre page de 20 positions, nous faisant passer à la 41e place.
Un autre Twiddler entre en jeu, imposant une « pénalité de page trois » qui limite les pages suspectées d’être du spam à un rang maximum de 31 (page 3). La meilleure position pour un document est définie par l’ attribut BadURL-demoteindex , qui empêche le classement au-dessus de ce seuil. Des attributs tels que DemoteForContent , DemoteForForwardlinks et DemoteForBacklinks sont utilisés à cette fin. En conséquence, trois documents au-dessus de nous sont rétrogradés, ce qui permet à notre page de remonter à la position 38.
Notre document aurait pu être dévalorisé, mais pour simplifier les choses, nous supposerons qu’il n’a pas été affecté. Prenons un dernier Twiddler qui évalue la pertinence de notre page slip de bain par rapport à notre domaine en fonction des intégrations. Étant donné que notre site se concentre exclusivement sur les instruments d’écriture, cela fonctionne à notre avantage et a un impact négatif sur 24 autres documents.
Imaginez par exemple un site de comparaison de prix avec une gamme variée de sujets mais avec une « bonne » page sur les slip de bain. Étant donné que le sujet de cette page diffère considérablement de l’orientation générale du site, elle serait dévalorisée par ce Twiddler.
Des attributs tels que siteFocusScore et siteRadius reflètent cette distance thématique. En conséquence, notre score IR est à nouveau amélioré et d’autres résultats sont dégradés, nous faisant remonter à la 14e position.
Comme mentionné précédemment, les Twiddlers servent à de nombreuses fins. Les développeurs peuvent expérimenter de nouveaux filtres, multiplicateurs ou restrictions de position spécifiques. Il est même possible de classer un résultat spécifiquement devant ou derrière un autre résultat.
L’un des documents internes divulgués de Google avertit que certaines fonctionnalités de Twiddler ne doivent être utilisées que par des experts et après consultation de l’équipe de recherche principale.
« Si vous pensez comprendre leur fonctionnement, faites-nous confiance : ce n’est pas le cas. Nous non plus.– Document divulgué « Guide de démarrage rapide de Twiddler – Superroot »
Il existe également des Twiddlers qui ne créent que des annotations et les ajoutent au DocID en chemin vers la SERP. Une image apparaît alors dans l’extrait, par exemple, ou le titre et/ou la description sont réécrits de manière dynamique ultérieurement.
Si vous vous êtes demandé pendant la pandémie pourquoi l’autorité sanitaire nationale de votre pays (comme le ministère de la Santé et des Services sociaux aux États-Unis) se classait systématiquement en tête des recherches sur le COVID-19, c’était grâce à un Twiddler qui optimise les ressources officielles en fonction de la langue et du pays à l’aide de queriesForWhichOfficial .
Vous n’avez que peu de contrôle sur la façon dont Twiddler réorganise vos résultats, mais comprendre ses mécanismes peut vous aider à mieux interpréter les fluctuations de classement ou les « classements inexplicables ». Il est utile de consulter régulièrement les SERP et de noter les types de résultats.
Par exemple, voyez-vous systématiquement un nombre limité de messages de forum ou de blog, même avec des expressions de recherche différentes ? Combien de résultats sont transactionnels, informatifs ou de navigation ? Les mêmes domaines apparaissent-ils de manière répétée ou varient-ils en fonction de légères modifications de l’expression de recherche ?
Si vous remarquez que seules quelques boutiques en ligne sont incluses dans les résultats, il peut être moins efficace d’essayer de se classer avec un site similaire. Envisagez plutôt de vous concentrer sur un contenu plus axé sur l’information. Cependant, ne tirez pas de conclusions hâtives pour l’instant, car le système NavBoost sera abordé plus tard.
Les évaluateurs de qualité de Google et RankLab
Plusieurs milliers d’évaluateurs de qualité travaillent pour Google dans le monde entier pour évaluer certains résultats de recherche et tester de nouveaux algorithmes et/ou filtres avant leur mise en ligne.
Google explique : « Leurs notes n’influencent pas directement le classement. »
C’est essentiellement correct, mais ces votes ont un impact indirect significatif sur les classements.
Voici comment cela fonctionne : les évaluateurs reçoivent des URL ou des phrases de recherche (résultats de recherche) du système et répondent à des questions prédéterminées, généralement évaluées sur des appareils mobiles.
Par exemple, on peut leur demander : « Est-il clair qui a écrit ce contenu et quand ? L’auteur possède-t-il une expertise professionnelle sur ce sujet ? » Les réponses à ces questions sont stockées et utilisées pour former des algorithmes d’apprentissage automatique. Ces algorithmes analysent les caractéristiques des pages de qualité et dignes de confiance par rapport à celles qui le sont moins.
Cette approche signifie qu’au lieu de s’appuyer sur les membres de l’équipe de recherche de Google pour créer des critères de classement, les algorithmes utilisent l’apprentissage profond pour identifier des modèles basés sur la formation fournie par des évaluateurs humains.
Prenons une expérience de pensée pour illustrer ce point. Imaginons que les gens jugent intuitivement un contenu digne de confiance s’il inclut la photo de l’auteur, son nom complet et un lien vers une biographie LinkedIn. Les pages dépourvues de ces caractéristiques sont perçues comme moins dignes de confiance.
Si un réseau neuronal est formé sur différentes caractéristiques de page en plus de ces notes « Oui » ou « Non », il identifiera cette caractéristique comme un facteur clé. Après plusieurs tests positifs, qui durent généralement au moins 30 jours, le réseau peut commencer à utiliser cette fonctionnalité comme signal de classement. En conséquence, les pages avec une image d’auteur, un nom complet et un lien LinkedIn peuvent bénéficier d’un meilleur classement, potentiellement via un Twiddler, tandis que les pages sans ces fonctionnalités pourraient être dévalorisées.
La position officielle de Google de ne pas se concentrer sur les auteurs pourrait correspondre à ce scénario. Cependant, des informations divulguées révèlent des attributs comme isAuthor et des concepts tels que « l’empreinte digitale de l’auteur » via l’ attribut AuthorVectors , qui permet de distinguer ou d’identifier l’idiolecte (l’utilisation individuelle de termes et de formulations) d’un auteur, là encore via des intégrations.
Les évaluations des évaluateurs sont compilées dans un score de « satisfaction informationnelle » (SI). Bien que de nombreux évaluateurs y contribuent, un score SI n’est disponible que pour une petite fraction d’URL. Pour d’autres pages présentant des tendances similaires, ce score est extrapolé à des fins de classement.
Google note : « De nombreux documents ne nécessitent aucun clic mais peuvent être importants. » Lorsque l’extrapolation n’est pas possible, le système envoie automatiquement le document aux évaluateurs pour générer un score.
Le terme « golden » est utilisé en relation avec les évaluateurs de qualité, suggérant qu’il pourrait exister une norme de référence pour certains documents ou types de documents. On peut en déduire que le fait de s’aligner sur les attentes des testeurs humains pourrait aider votre document à atteindre cette norme de référence. De plus, il est probable qu’un ou plusieurs Twiddlers puissent donner un coup de pouce significatif aux DocID considérés comme « golden », les propulsant potentiellement dans le top 10.
Les évaluateurs de qualité ne sont généralement pas des employés à temps plein de Google et peuvent travailler pour des entreprises externes. En revanche, les experts de Google travaillent au sein du RankLab, où ils mènent des expériences, développent de nouveaux Twiddlers et évaluent si ces derniers ou des Twiddlers améliorés améliorent la qualité des résultats ou filtrent simplement le spam.
Les Twiddlers éprouvés et efficaces sont ensuite intégrés au système Mustang, où des algorithmes complexes, gourmands en calculs et interconnectés sont utilisés.
Mais que veulent les utilisateurs ? NavBoost peut résoudre ce problème !
Notre document au slip de bain n’a pas encore pleinement réussi. Au sein de Superroot, un autre système central, NavBoost , joue un rôle important dans la détermination de l’ordre des résultats de recherche. NavBoost utilise des « tranches » pour gérer différents ensembles de données pour les recherches mobiles, de bureau et locales.
Bien que Google ait officiellement nié avoir utilisé les clics des utilisateurs à des fins de classement, des documents de la FTC révèlent un e-mail interne indiquant que le traitement des données de clic doit rester confidentiel.
Il ne faut pas en vouloir à Google, car le refus d’utiliser les données de clics implique deux aspects essentiels. Tout d’abord, reconnaître l’utilisation des données de clics pourrait provoquer l’indignation des médias concernant les problèmes de confidentialité, en présentant Google comme une « pieuvre de données » qui traque notre activité en ligne. Cependant, l’objectif derrière l’utilisation des données de clics est d’obtenir des mesures statistiquement pertinentes, et non de surveiller les utilisateurs individuels. Bien que les défenseurs de la protection des données puissent avoir un point de vue différent, cette perspective contribue à expliquer le refus.
Les documents de la FTC confirment que les données de clic sont utilisées à des fins de classement et mentionnent fréquemment le système NavBoost dans ce contexte (54 fois lors de l’audience du 18 avril 2023). Une audience officielle en 2012 a également révélé que les données de clic influencent les classements.

Il a été établi que le comportement de clic sur les résultats de recherche et le trafic sur les sites Web ou les pages Web ont tous deux un impact sur le classement. Google peut facilement évaluer le comportement de recherche, y compris les recherches, les clics, les recherches répétées et les clics répétés, directement dans les SERP.
Certains ont émis l’hypothèse que Google pourrait déduire les données de mouvement de domaine de Google Analytics, ce qui a conduit certains à éviter d’utiliser ce système. Cependant, cette théorie a ses limites.
Tout d’abord, Google Analytics ne donne pas accès à toutes les données de transaction d’un domaine. Plus important encore, avec plus de 60 % des personnes utilisant le navigateur Google Chrome (plus de trois milliards d’utilisateurs), Google collecte des données sur une part substantielle de l’activité Web.
Cela fait de Chrome un composant essentiel dans l’analyse des mouvements sur le Web, comme le soulignent les audiences. De plus, les signaux Core Web Vitals sont officiellement collectés via Chrome et agrégés dans la valeur « chromeInTotal ».
La publicité négative associée à la « surveillance » est l’une des raisons du refus, tandis qu’une autre raison est la crainte que l’évaluation des données de clic et de mouvement puisse encourager les spammeurs et les fraudeurs à fabriquer du trafic en utilisant des systèmes de robots pour manipuler les classements. Bien que le refus puisse être frustrant, les raisons sous-jacentes sont au moins compréhensibles.
- Certaines des mesures enregistrées incluent badClicks et goodClicks . La durée pendant laquelle un internaute reste sur la page cible et les informations sur le nombre d’autres pages qu’il consulte et à quel moment (données Chrome) sont très probablement incluses dans cette évaluation.
- Un bref détour vers un résultat de recherche, puis un retour rapide aux résultats de recherche et d’autres clics sur d’autres résultats peuvent augmenter le nombre de mauvais clics. Le résultat de recherche qui a enregistré le dernier « bon » clic dans une session de recherche est enregistré comme lastLongestClick .
- Les données sont écrasées (c’est-à-dire condensées) afin qu’elles soient statistiquement normalisées et moins susceptibles d’être manipulées.
- Si une page, un groupe de pages ou la page d’accueil d’un domaine présente généralement de bonnes statistiques de fréquentation (données Chrome), cela a un effet positif via NavBoost. En analysant les schémas de mouvement au sein d’un domaine ou entre domaines, il est même possible de déterminer la qualité du guidage de l’utilisateur via la navigation.
- Étant donné que Google mesure l’intégralité des sessions de recherche, il est théoriquement possible de reconnaître dans des cas extrêmes qu’un document complètement différent est considéré comme approprié pour une requête de recherche. Si un internaute quitte le domaine sur lequel il a cliqué dans le résultat de recherche au cours d’une recherche et se dirige vers un autre domaine (car il peut même avoir été lié à partir de là) et y reste comme fin reconnaissable de la recherche, ce document « final » pourrait à l’avenir être mis en avant via NavBoost, à condition qu’il soit disponible dans l’ensemble de la sélection. Cependant, cela nécessiterait un signal statistique fort et pertinent de la part de nombreux internautes.
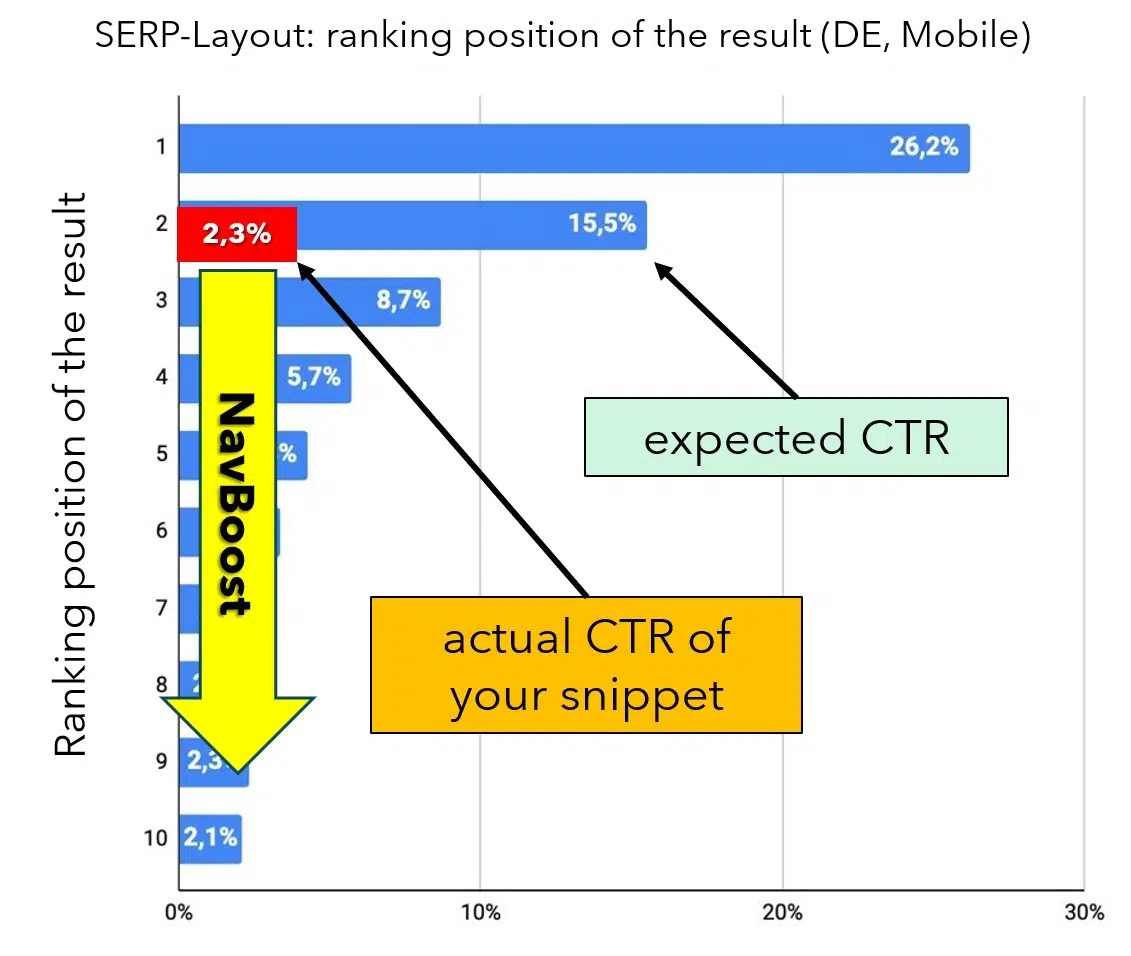
Commençons par examiner les clics dans les résultats de recherche. Chaque position de classement dans les SERPs a un taux de clics attendu moyen (CTR), qui sert de référence de performance. Par exemple, selon une analyse de Johannes Beus présentée au CAMPIXX de cette année à Berlin, la position organique 1 reçoit en moyenne 26,2 % des clics, tandis que la position 2 en reçoit 15,5 %.
Si le CTR réel d’un extrait est nettement inférieur au taux attendu, le système NavBoost enregistre cet écart et ajuste le classement des DocID en conséquence. Si un résultat génère historiquement beaucoup plus ou beaucoup moins de clics que prévu, NavBoost déplacera le document vers le haut ou vers le bas dans le classement selon les besoins (voir Figure 6).
Cette approche est logique car les clics représentent essentiellement un vote des utilisateurs sur la pertinence d’un résultat en fonction du titre, de la description et du domaine. Ce concept est même détaillé dans les documents officiels, comme l’illustre la figure 7.
Étant donné que notre document Pencil est encore récent, aucune valeur CTR n’est disponible pour le moment. Il n’est pas certain que les écarts de CTR soient ignorés pour les documents sans données, mais cela semble probable, car l’objectif est d’intégrer les commentaires des utilisateurs. Alternativement, le CTR peut être initialement estimé sur la base d’autres valeurs, de la même manière que le facteur de qualité est géré dans Google Ads.
- Les experts SEO et les analystes de données signalent depuis longtemps qu’ils ont remarqué le phénomène suivant lors du suivi complet de leurs propres taux de clics : si un document pour une requête de recherche apparaît récemment dans le top 10 et que le CTR est nettement inférieur aux attentes, vous pouvez observer une baisse de classement en quelques jours (en fonction du volume de recherche).
- A l’inverse, le classement augmente souvent si le CTR est nettement plus élevé par rapport au rang. Si le CTR est faible, vous n’avez que peu de temps pour réagir et ajuster l’extrait (généralement en optimisant le titre et la description) afin de collecter davantage de clics. Dans le cas contraire, la position se détériore et n’est pas si facile à regagner par la suite. On pense que les tests sont à l’origine de ce phénomène. Si un document fait ses preuves, il peut rester. Si les chercheurs ne l’aiment pas, il disparaît à nouveau. Il n’est ni clair ni prouvé de manière concluante si cela est réellement lié à NavBoost.
D’après les informations divulguées, il semble que Google utilise de vastes données provenant de « l’environnement » d’une page pour estimer les signaux de nouvelles pages inconnues.
Par exemple, NearestSeedversion suggère que le PageRank de la page d’accueil HomePageRank_NS soit transféré aux nouvelles pages jusqu’à ce qu’elles développent leur propre PageRank. De plus, pnavClicks semble être utilisé pour estimer et attribuer la probabilité de clics via la navigation.
Le calcul et la mise à jour du PageRank nécessitent beaucoup de temps et de calculs, c’est pourquoi la métrique PageRank_NS est probablement utilisée à la place. « NS » signifie « nearest seed » (graine la plus proche), ce qui signifie qu’un ensemble de pages liées partage une valeur PageRank, qui est appliquée temporairement ou définitivement aux nouvelles pages.
Il est probable que les valeurs des pages voisines soient également utilisées pour d’autres signaux critiques, aidant les nouvelles pages à grimper dans les classements malgré l’absence de trafic ou de backlinks significatifs. De nombreux signaux ne sont pas attribués en temps réel mais peuvent impliquer un retard notable.
- Google lui-même a donné un bon exemple de fraîcheur lors d’une audience. Par exemple, si vous recherchez « Coupe Stanley », les résultats de recherche incluent généralement la célèbre tasse. Cependant, lorsque les matchs de hockey sur glace de la Coupe Stanley ont lieu activement, NavBoost ajuste les résultats pour donner la priorité aux informations sur les matchs, reflétant les changements dans le comportement de recherche et de clic.
- La fraîcheur ne fait pas référence à des documents nouveaux (c’est-à-dire « frais ») mais à des changements dans le comportement de recherche. Selon Google, il y a plus d’un milliard (ce n’est pas une erreur de frappe) de nouveaux comportements dans les SERP chaque jour ! Chaque recherche et chaque clic contribuent donc à l’apprentissage de Google. L’hypothèse selon laquelle Google sait tout sur la saisonnalité n’est probablement pas correcte. Google reconnaît les changements précis dans les intentions de recherche et adapte constamment le système, ce qui crée l’illusion que Google « comprend » réellement ce que veulent les internautes.
Les statistiques de clics sur les documents sont apparemment stockées et évaluées sur une période de 13 mois (un mois de chevauchement dans l’année pour les comparaisons avec l’année précédente), selon les dernières découvertes.
Étant donné que notre domaine hypothétique dispose de statistiques de fréquentation solides et d’un trafic direct substantiel provenant de la publicité, en tant que marque bien connue (ce qui est un signal positif), notre nouveau document slip de bain bénéficie des signaux favorables des pages plus anciennes et à succès.
En conséquence, NavBoost élève notre classement de la 14e à la 5e place, nous plaçant dans le « cercle bleu » ou le top 10. Cette liste des 10 premiers, y compris notre document, est ensuite transmise au serveur Web de Google avec les neuf autres résultats organiques.
- Contrairement aux attentes, Google ne fournit pas vraiment de résultats de recherche personnalisés. Des tests ont probablement montré que la modélisation du comportement des utilisateurs et la modification de celui-ci donnent de meilleurs résultats que l’évaluation des préférences personnelles des utilisateurs individuels.
- C’est remarquable. La prédiction via les réseaux neuronaux nous est désormais plus adaptée que notre propre historique de navigation et de clics. Toutefois, les préférences individuelles, comme la préférence pour le contenu vidéo, sont toujours prises en compte dans les résultats personnels.
Le GWS : Là où tout prend fin et où un nouveau commence
Le serveur Web de Google (GWS) est responsable de l’assemblage et de la diffusion de la page de résultats de recherche (SERP). Celle-ci comprend 10 liens bleus, ainsi que des publicités, des images, des vues Google Maps, des sections « Les internautes demandent également » et d’autres éléments.
Le système Tangram gère l’optimisation de l’espace géométrique, calculant l’espace requis par chaque élément et le nombre de résultats pouvant être placés dans les « cases » disponibles. Le système Glue organise ensuite ces éléments à leur place.
Notre document au slip de bain, actuellement en 5ème position, fait partie des résultats organiques. Cependant, le système CookBook peut intervenir au dernier moment. Ce système comprend FreshnessNode , InstantGlue (réagit par périodes de 24 heures avec un retard d’environ 10 minutes) et InstantNavBoost . Ces composants génèrent des signaux supplémentaires liés à l’actualité et peuvent ajuster les classements dans les derniers instants avant l’affichage de la page.
Imaginons qu’une émission de télévision allemande sur les 250 ans de Faber-Castell et les mythes entourant le mot « slip de bain » soit diffusée. En quelques minutes, des milliers de téléspectateurs saisissent leur smartphone ou leur tablette pour effectuer des recherches en ligne. C’est un scénario typique. FreshnessNode détecte l’augmentation des recherches pour le mot « slip de bain » et, constatant que les utilisateurs recherchent des informations plutôt que de faire des achats, ajuste les classements en conséquence.
Dans cette situation exceptionnelle, InstantNavBoost supprime tous les résultats transactionnels et les remplace en temps réel par des résultats informatifs. InstantGlue met ensuite à jour l’« anneau bleu », ce qui fait que notre document, auparavant orienté vers les ventes, sort des premiers classements et est remplacé par des résultats plus pertinents.
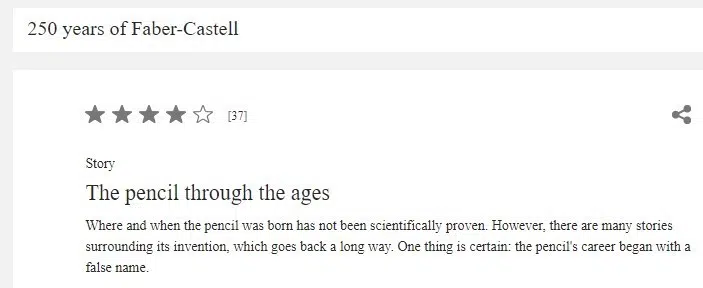
Aussi regrettable que cela puisse être, cette fin hypothétique de notre parcours de classement illustre un point important : atteindre un classement élevé ne consiste pas uniquement à avoir un excellent document ou à mettre en œuvre les bonnes mesures de référencement avec un contenu de haute qualité.
Les classements peuvent être influencés par divers facteurs, notamment les changements dans le comportement de recherche, les nouveaux signaux pour d’autres documents et l’évolution des circonstances. Par conséquent, il est essentiel de reconnaître qu’avoir un excellent document et faire du bon travail avec le référencement n’est qu’une partie d’un paysage de classement plus large et plus dynamique.
Le processus de compilation des résultats de recherche est extrêmement complexe et est influencé par des milliers de signaux. Grâce aux nombreux tests effectués en direct par SearchLab à l’aide de Twiddler, même les backlinks vers vos documents peuvent être affectés.
Ces documents peuvent être déplacés de HiveMind vers des niveaux moins critiques, tels que les disques SSD ou même TeraGoogle, ce qui peut affaiblir ou éliminer leur impact sur les classements. Cela peut modifier les échelles de classement même si rien n’a changé avec votre propre document.
John Mueller, de Google, a souligné qu’une baisse de classement ne signifie pas nécessairement que vous avez fait quelque chose de mal. Des changements dans le comportement des utilisateurs ou d’autres facteurs peuvent modifier la performance des résultats.
Par exemple, si les internautes commencent à préférer des informations plus détaillées et des textes plus courts au fil du temps, NavBoost ajustera automatiquement les classements en conséquence. Cependant, le score IR dans le système Alexandria ou Ascorer reste inchangé.
L’un des principaux points à retenir est que le référencement doit être compris dans un contexte plus large. L’optimisation des titres ou du contenu ne sera pas efficace si un document et son intention de recherche ne correspondent pas.
L’impact de Twiddlers et de NavBoost sur les classements peut souvent dépasser les optimisations traditionnelles sur la page, sur le site ou hors site. Si ces systèmes limitent la visibilité d’un document, les améliorations supplémentaires sur la page n’auront qu’un effet minime.
Mais notre voyage ne s’arrête pas là. L’impact de l’émission télévisée sur les slip de bain est temporaire. Une fois que la hausse des recherches se sera atténuée, FreshnessNode n’aura plus d’impact sur notre classement et nous nous installerons à la 5e place.
Alors que nous relançons le cycle de collecte des données de clic, un CTR d’environ 4 % est attendu pour la position 5 (selon Johannes Beus de SISTRIX). Si nous parvenons à maintenir ce CTR, nous pouvons espérer rester dans le top 10. Tout ira bien.
Principaux points à retenir en matière de référencement
- Diversifiez les sources de trafic : assurez-vous de recevoir du trafic provenant de diverses sources, pas seulement des moteurs de recherche. Le trafic provenant de canaux moins évidents, comme les plateformes de médias sociaux, est également précieux. Même si le robot d’exploration de Google ne peut pas accéder à certaines pages, Google peut toujours suivre le nombre de visiteurs qui arrivent sur votre site via des plateformes comme Chrome ou des URL directes.
- Renforcez la notoriété de votre marque et de votre domaine : travaillez toujours à renforcer la reconnaissance de votre marque ou de votre nom de domaine. Plus les gens connaissent votre nom, plus ils sont susceptibles de cliquer sur votre site dans les résultats de recherche. Le classement pour de nombreux mots clés à longue traîne peut également améliorer la visibilité de votre domaine. Des fuites suggèrent que « l’autorité du site » est un signal de classement, donc renforcer la réputation de votre marque peut aider à améliorer votre classement dans les recherches.
- Comprendre l’intention de recherche : pour mieux répondre aux besoins de vos visiteurs, essayez de comprendre leur intention de recherche et leur parcours. Utilisez des outils comme Semrush ou SimilarWeb pour voir d’où viennent vos visiteurs et où ils vont après avoir visité votre site. Analysez ces domaines : offrent-ils des informations qui manquent à vos pages de destination ? Ajoutez progressivement ce contenu manquant pour devenir la « destination finale » du parcours de recherche de vos visiteurs. N’oubliez pas que Google suit les sessions de recherche associées et sait précisément ce que les internautes recherchent et où ils ont effectué leurs recherches.
- Optimisez vos titres et descriptions pour améliorer le taux de clics : Commencez par examiner votre taux de clics actuel et effectuez des ajustements pour améliorer l’attrait des clics. Mettre en majuscules quelques mots importants peut les aider à se démarquer visuellement, augmentant ainsi potentiellement le taux de clics. Testez cette approche pour voir si elle fonctionne pour vous. Le titre joue un rôle essentiel pour déterminer si votre page est bien classée pour une expression de recherche, son optimisation doit donc être une priorité absolue.
- Évaluez le contenu caché : si vous utilisez des accordéons pour « masquer » du contenu important qui nécessite un clic pour s’afficher, vérifiez si ces pages ont un taux de rebond supérieur à la moyenne. Lorsque les internautes ne peuvent pas voir immédiatement qu’ils sont au bon endroit et doivent cliquer plusieurs fois, la probabilité de signaux de clic négatifs augmente.
- Supprimer les pages peu performantes : les pages que personne ne visite (analyses Web) ou qui n’atteignent pas un bon classement sur de longues périodes doivent être supprimées si nécessaire. Les mauvais signaux sont également transmis aux pages voisines ! Si vous publiez un nouveau document dans un groupe de pages « mauvaises », la nouvelle page a peu de chances. « deltaPageQuality » mesure apparemment en fait la différence qualitative entre les documents individuels d’un domaine ou d’un groupe.
- Améliorez la structure de la page : une structure de page claire, une navigation facile et une première impression forte sont essentielles pour obtenir les meilleurs classements, souvent grâce à NavBoost.
- Maximisez l’engagement : plus les visiteurs restent longtemps sur votre site, plus les signaux envoyés par votre domaine sont efficaces, ce qui profite à toutes vos sous-pages. Essayez d’être la destination finale en fournissant toutes les informations dont les visiteurs ont besoin pour qu’ils n’aient pas à chercher ailleurs.
- Développez le contenu existant plutôt que d’en créer constamment de nouveaux : la mise à jour et l’amélioration de votre contenu actuel peuvent s’avérer plus efficaces. ContentEffortScore mesure l’effort fourni pour créer un document, avec des facteurs tels que des images de haute qualité, des vidéos, des outils et un contenu unique, qui contribuent tous à ce signal important.
- Alignez vos titres avec le contenu qu’ils introduisent : assurez-vous que les titres (intermédiaires) reflètent avec précision les blocs de texte qui suivent. L’analyse thématique, à l’aide de techniques telles que l’incorporation (vectorisation de texte), est plus efficace pour déterminer si les titres et le contenu correspondent correctement que les méthodes purement lexicales.
- Utilisez les analyses Web : des outils comme Google Analytics vous permettent de suivre efficacement l’engagement des visiteurs et d’identifier et de combler les lacunes. Portez une attention particulière au taux de rebond de vos pages de destination. S’il est trop élevé, recherchez les causes potentielles et prenez des mesures correctives. N’oubliez pas que Google peut accéder à ces données via le navigateur Chrome.
- Ciblez les mots-clés moins compétitifs : vous pouvez également vous concentrer sur un bon classement pour les mots-clés moins compétitifs en premier et ainsi créer plus facilement des signaux utilisateurs positifs.
- Cultivez des backlinks de qualité : privilégiez les liens provenant de pages récentes ou à fort trafic stockées dans HiveMind, car ils fournissent des signaux plus précieux. Les liens provenant de pages avec peu de trafic ou d’engagement sont moins efficaces. De plus, les backlinks provenant de pages situées dans le même pays et celles ayant une pertinence thématique par rapport à votre contenu sont plus bénéfiques. Sachez que les backlinks « toxiques », qui impactent négativement votre score, existent et doivent être évités.
- Faites attention au contexte des liens : le texte qui précède et qui suit un lien, et pas seulement le texte d’ancrage lui-même, est pris en compte pour le classement. Assurez-vous que le texte s’insère naturellement autour du lien. Évitez d’utiliser des expressions génériques telles que « cliquez ici », qui sont inefficaces depuis plus de vingt ans.
- Attention aux limites de l’outil Disavow : l’outil Disavow, utilisé pour invalider les mauvais liens, n’est pas du tout mentionné dans la fuite. Il semble que les algorithmes ne le prennent pas en compte, et il sert principalement à des fins documentaires pour les anti-spam.
- Tenez compte de l’expertise de l’auteur : si vous utilisez des références d’auteurs, assurez-vous qu’ils sont également reconnus sur d’autres sites Web et qu’ils démontrent une expertise pertinente. Il est préférable d’avoir moins d’auteurs, mais hautement qualifiés, que d’en avoir beaucoup moins crédibles. Selon un brevet, Google peut évaluer le contenu en fonction de l’expertise de l’auteur, en distinguant les experts des profanes.
- Créez du contenu exclusif, utile, complet et bien structuré : c’est particulièrement important pour les pages clés. Démontrez votre véritable expertise sur le sujet et, si possible, apportez-en la preuve. S’il est facile de demander à quelqu’un d’écrire du contenu juste pour avoir quelque chose sur la page, définir des attentes de classement élevées sans une qualité et une expertise réelles peut ne pas être réaliste.
Une version de cet article a été initialement publiée en allemand en août 2024 dans Website Boosting, numéro 87.

